Django 쿼리셋을 데이터프레임으로 빠르게 처리하기
Django는 ORM(Object-Relational Mapping)을 통해 데이터를 생성하고 읽고 갱신하고 삭제하는 기능(CRUD, Create Read Update Delete)을 수행한다.
이 중에서 읽어오는 기능을 수행할 때 '어떻게 하면 좀 더 빠르게 처리할 수 있을까?'라는 생각에서 시작하게 되었다. 일단 증권사 API와 SQL에 저장된 데이터를 합쳐서 원하는 기능을 구현하고자 했다.
API로 데이터를 서버에서 가져오는 기능과 Django의 ORM으로 쿼리셋(QuerySet)을 가져오는 기능을 수행해야 하는데, API는 지정된 속도 제한이 있어 한계가 있어 장고의 처리 속도를 빠르게 할 방법을 찾아야 했다.
기본
API로 데이터 요청만 처리했을 때 걸린 시간이다. 꽤 걸리지만 이 방법이 최선이었기에 이보다 빠르게 처리하려면 정기적으로 정해진 시간대에 미리 데이터를 수집해놓는 것을 생각해야 할 듯하다.
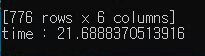
방법 1 (objects.get 사용)
'objects.get'은 괄호 조건에 맞는 열 값을 가져오며, 쿼리셋이 아닌 값으로 가져오기 때문에 바로 사용할 수 있다. 그러나 처리 시간이 늘어났다는 단점이 있다. 향후에 데이터가 더 많아지게 되면 차이는 더 커지게 될 것이다.
me = test_table.objects.get(name="조대리")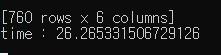
방법 2 (objects.values_list + pandas DataFrame 사용)
그래서 열심히 생각해 보던 중... '일단 데이터를 가져온 뒤에, 데이터프레임에서 원하는 데이터를 골라 사용하면 어떨까?' 하는 생각이 들어 시도해 보았다.
'objects.values_list'에 대해 설명하자면, values_list()를 사용하면 key:value로 쌍으로 된 형태가 아닌 tuple 형태의 값만 보유한 리스트로 가져오게 된다. 그런 다음 형태를 데이터프레임으로 전환한다.
API로만 했을 때 보다 빨라진 건 이상하지만... 오차 정도라고 생각하고, objects.get으로 구현한 것보다는 유의미한 속도 향상을 이뤄낼 수 있었다.
me = test_table.objects.values_list("name", "job")
df_me = pd.DataFrame(list(me), columns=["name", "job"])